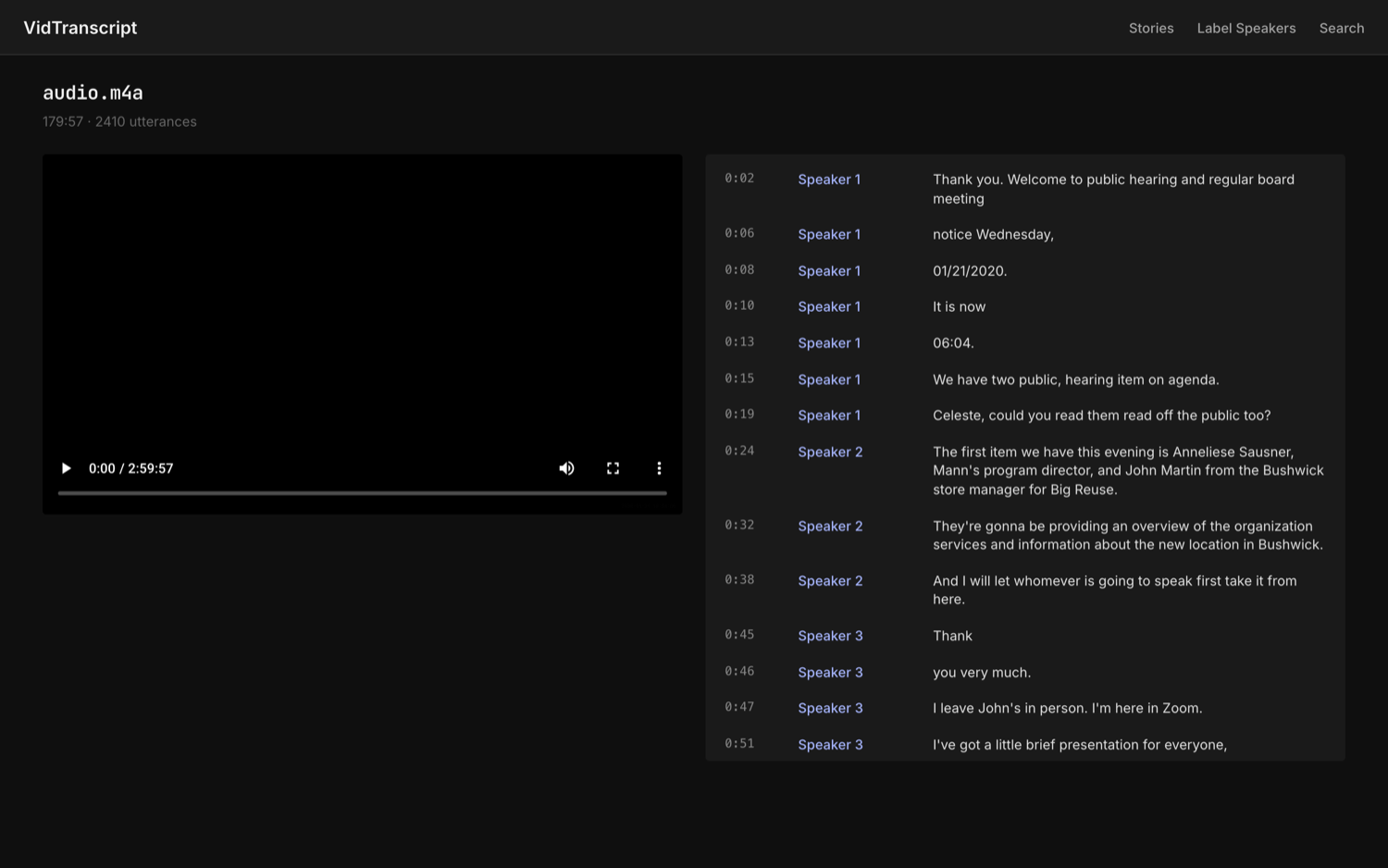
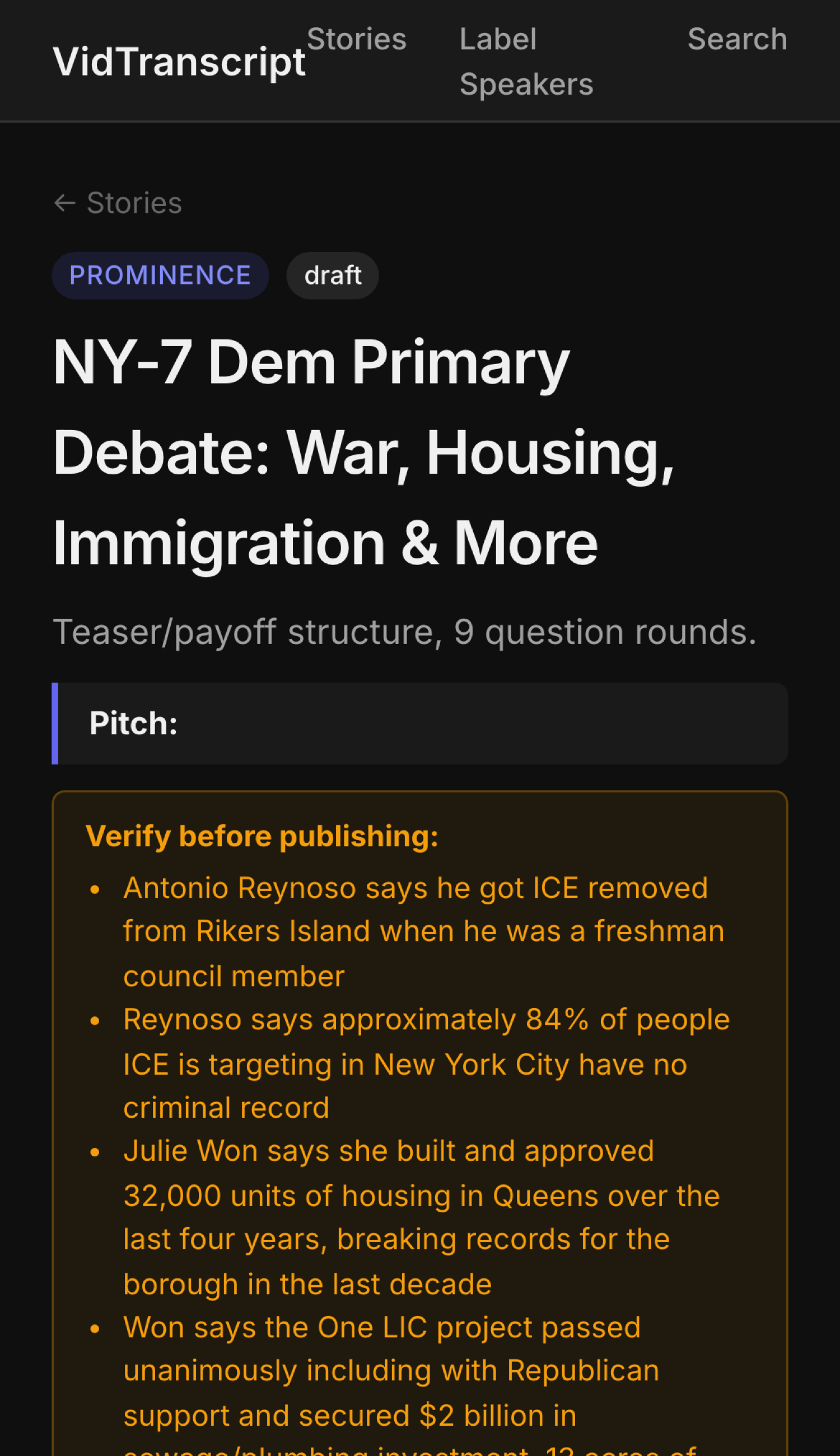
01 · the promisescene 01 / 12
Paste a civic URL.
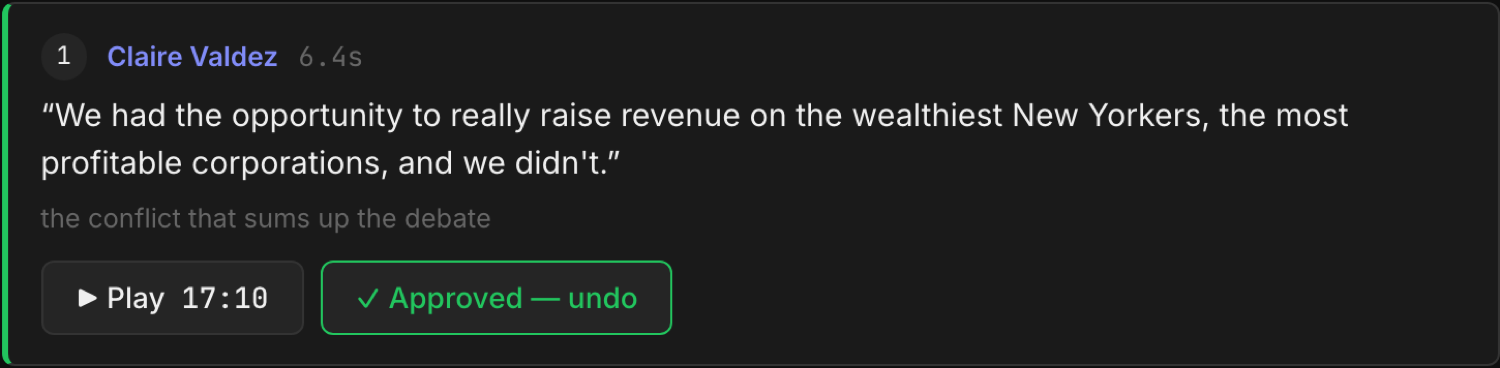
Get a clip whose every quote is provably real.
what vidtranscript is
vidtranscript is the code-enforced-correctness civic-video pipeline that lets one operator — no engineer, no CLI — turn a pasted civic-video URL or uploaded footage into a speaker-attributed transcript, provably-spoken grounded quotes with an article draft, and broadcast-looking captioned social video, where the load-bearing claims are decided by deterministic code, not by the model.
Paste a civic URL. Get a trustworthy clip. The quote is provably real — and the code, not the model, guarantees it.
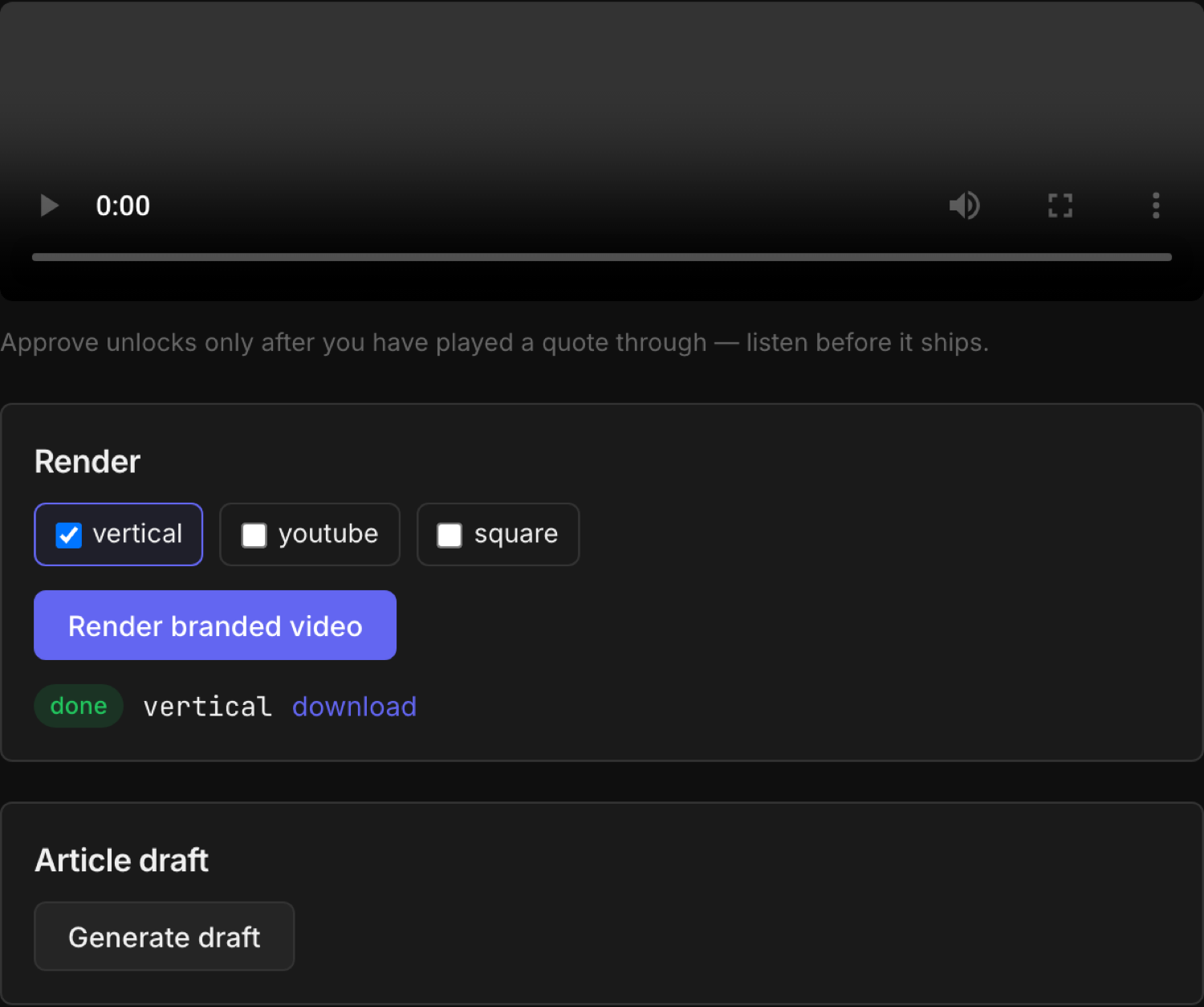
video frame · 9:16

render_frame_captions_01_reynoso.png — the finished clip you post